The Future Stack: AI + WebAssembly + IoT¶
The Shift from Firmware to Workloads¶
For decades, IoT devices have been defined by their firmware.
Functionality was embedded directly into the device at the time of deployment, compiled specifically for the target hardware, and tightly coupled to the vendor’s software stack.
Once deployed, that firmware would remain largely unchanged — updated only when necessary, and often with significant effort and risk. This model worked when devices were simple, purpose-built, and rarely evolved after installation.
That is no longer the case.
Today’s devices are expected to do far more than execute a fixed set of instructions. They are expected to adapt to changing requirements, integrate with evolving systems, and incorporate new capabilities long after deployment.
This is particularly true as AI begins to move closer to the edge, where models and logic are continuously refined based on new data and operational feedback. In this environment, static firmware becomes a constraint.
The limitation is not only technical — it is structural.
Firmware is inherently tied to hardware. It is built using vendor-specific tool chains, relies on proprietary abstractions, and must often be rebuilt entirely when underlying components change — even small updates can require full system validation, redeployment, and, in some cases, physical intervention. As devices scale into fleets and lifetimes extend into decades, this approach does not hold.
A different model is required.
Instead of treating firmware as the primary unit of functionality, devices must begin to treat logic as a deployable entity — independent from the underlying system that executes it. This is the shift — from firmware to workloads.

Figure 8: Evolution From Firmware to Workloads
In this model, the device still provides a stable foundation — handling core responsibilities such as hardware control, security boundaries, and communication. But the functionality that defines what the device does is no longer permanently embedded within that foundation.
It is delivered, updated, and replaced.
Workloads introduce a new level of flexibility. They allow functionality to evolve without requiring a full system rebuild. They enable new capabilities to be introduced incrementally, rather than as part of large, infrequent updates.
They also create the possibility for multiple stakeholders — internal teams, partners, or third parties — to contribute logic without direct access to the underlying firmware. This does not eliminate the need for firmware — it changes its role.
Firmware becomes the platform. Workloads become the behavior. This distinction is subtle, but it has far-reaching implications. It changes how systems are designed. It changes how updates are delivered. It changes how value is created over time. Most importantly, it aligns the Edge with a model that has already proven effective elsewhere.
In cloud environments, applications are no longer tied to infrastructure. They are packaged, deployed, and managed independently. This separation enables scalability, portability, and continuous delivery.
The same principle is now beginning to emerge at the device level.
It is no longer a question of whether devices can be updated — it is whether they can evolve.
AI at the Edge Requires Continuous Evolution¶
The introduction of AI at the edge changes the nature of IoT systems.
Traditional device logic is deterministic. It follows predefined rules, reacts to known inputs, and produces predictable outputs. Once deployed, that logic may remain valid for long periods of time, requiring only occasional updates.
AI does not behave this way — AI models are not static.
They are trained, refined, and improved over time. Their effectiveness depends on data, context, and continuous iteration. As conditions change — whether environmental, operational, or behavioral — the models must adapt to remain relevant and accurate.
This introduces a fundamental shift in how devices are expected to operate.
An AI-enabled device is no longer defined solely by its hardware or its initial firmware. It is defined by the models and logic it runs — and those models are expected to evolve.
This creates new requirements: models must be updated more frequently, logic must be adjusted without disrupting the entire system, and new capabilities must be introduced without rebuilding from scratch. In many cases, multiple versions of a model may need to coexist, be tested, or be rolled back based on real-world performance.
The traditional firmware model is not designed for this level of change.
Reflashing an entire device to update a model is inefficient and risky. It introduces downtime, increases the likelihood of failure, and makes rapid iteration impractical — especially at scale.
As the number of devices grows, so does the cost and complexity of maintaining them. AI turns devices into evolving systems — evolving systems require a different foundation.
It is a matter of lifecycle management — the ability to deploy, update, validate, and manage AI-driven logic over time becomes a core requirement of the system itself. Without it, even the most advanced models cannot be effectively utilized in real-world deployments.
This reinforces the shift introduced earlier. If devices are expected to evolve, the logic they execute must be treated as something that can be independently delivered, updated, and controlled.
Workloads are not an optimization — they are a necessity. AI at the edge does not just increase what devices can do — it increases how often they need to change.
The Need for a New Execution Model¶
The shift toward workloads and continuously evolving logic introduces a fundamental requirement:
Devices must be able to execute code that was not present at the time they were deployed.
This may seem like a natural extension of existing update mechanisms.
In practice, it is not. Traditional IoT systems are built around a tightly coupled model, where application logic, system services, and hardware interaction are all bound together within a single firmware image. This model assumes that functionality is known in advance, compiled as a whole, and deployed as a single unit.
It is optimized for stability — not for change. When new logic needs to be introduced, the entire system must be rebuilt, validated, and redeployed. Even minor changes require coordination across components that were never designed to evolve independently.
This creates friction. As the frequency of updates increases — as it does with AI-driven systems — that friction becomes a barrier. Updates become slower, risk increases, and operational overhead grows — what was once a manageable process becomes a bottleneck.
The limitation is not only in how updates are delivered, but in how execution is defined. In the current model, code is trusted by default. Once it is part of the firmware, it has access to the full capabilities of the system.
There is no inherent mechanism to constrain behavior, limit access, or isolate execution in a meaningful way. This is acceptable when all logic is tightly controlled and rarely changes.
It does not scale when logic is dynamic, frequently updated, or sourced from multiple contributors.
A different execution model is required. This model must support independent units of logic — workloads — that can be deployed and updated without requiring full system replacement.
It must allow these workloads to run in a controlled environment, with clearly defined boundaries and explicit access to system resources. It must also operate within the constraints of Edge environments, where memory is limited, compute is bounded, and deterministic behavior is often required.
These requirements are not optional. They are the foundation for enabling continuous evolution at the device level. The challenge is that existing execution models do not satisfy them.
Traditional firmware models are too rigid. Operating system-based approaches are too heavy. Containerization, while effective in cloud environments, does not translate to microcontroller-class devices.
This represents a gap — not in capability, but in alignment.
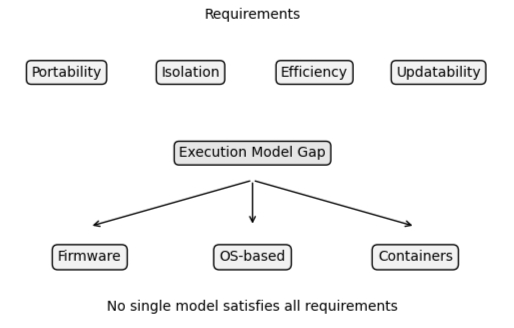
Figure 9: Gap Between Requirements and Existing Execution Models
What is needed is a model that combines:
- Portability — the ability to run the same logic across different hardware
- Isolation — the ability to constrain and control execution
- Efficiency — the ability to operate within strict resource limits
- Updatability — the ability to evolve logic independently over time
The industry understands the direction — dynamic workloads, secure execution, independent updates — but lacks a model that brings these requirements together in a way that works under real-world constraints. The next step is to define that model.
WebAssembly as a Universal Execution Layer¶
The requirements outlined so far — portability, isolation, efficiency, and independent updatability — are not unique to IoT.
They have emerged in other domains before. In the cloud, similar challenges led to the rise of containerization. In the browser, they led to the introduction of a secure execution model for running untrusted code. In both cases, the solution was not to extend existing systems indefinitely, but to introduce a new execution layer.
A similar transition is now taking shape at the edge.
WebAssembly is emerging as a candidate for that layer. Originally developed to enable safe, high-performance execution within web browsers, WebAssembly was designed around a set of principles that align closely with the needs of modern Edge systems. It is compact, deterministic, sandboxed by design, and portable across architectures and languages.
These properties are not incidental — they are what allow code to be executed in environments where trust is limited and resources are constrained.
WebAssembly introduces a new way of thinking about device logic.
Instead of compiling functionality directly into firmware, logic can be compiled into a standardized, portable format. This format can then be delivered to devices and executed within a controlled environment, independent of the underlying hardware and vendor-specific software stack.
This aligns directly with the shift toward workloads. Logic becomes something that can be packaged, deployed, and updated independently — without requiring full system replacement.
It also introduces a consistent execution model.
The same logic can run across different devices. The same constraints can be applied regardless of hardware. The same lifecycle processes can be used to manage behavior over time. This is the potential.
WebAssembly provides a foundation for portable, sandboxed execution at the device level — something that has been largely absent in IoT systems built around monolithic firmware models.
However, it is important to distinguish between potential and reality.
WebAssembly was not designed specifically for microcontroller-class devices. Its initial adoption has been in environments with significantly more resources — browsers, servers, and edge gateways.
The tooling, runtimes, and supporting ecosystems reflect those origins.
As a result, while the execution model is well aligned with the needs of IoT, its current implementations do not yet fully satisfy the constraints of embedded systems.
The model is right — the implementation is still evolving. The question, then, is not whether WebAssembly is relevant to IoT. It is how it can be adapted to meet the realities of resource-constrained devices.
The Software Sandbox¶
The introduction of a new execution layer is not only about portability.
It is about control.
In traditional firmware-based systems, code runs with implicit trust. Once logic is compiled into the system, it operates with broad access to device resources. It can interact with hardware directly, allocate memory freely within system limits, and influence overall system behavior without meaningful restriction.
This model assumes that all code is trusted. It also assumes that all code is static. As systems evolve toward dynamic workloads, these assumptions no longer hold.
Code may be updated frequently. It may originate from different teams. It may be introduced after deployment. In this context, implicit trust becomes a liability.
This is where the concept of a software sandbox becomes essential.
A sandbox defines a controlled execution environment in which code can run, but only within explicitly defined boundaries. It restricts what the code can access, how it can interact with the system, and what side effects it can produce.
In the case of WebAssembly, this constraint is fundamental to its design.
WebAssembly modules do not have direct access to system resources — they cannot interact with hardware unless explicitly permitted, cannot access memory outside of their defined space, and cannot perform operations beyond what is exposed to them. All interaction is intentional.
This changes the execution model in a fundamental way. Instead of trusting code because it is part of the system, the system defines what the code is allowed to do.
This distinction is critical.
The sandbox provides isolation at the level of execution. Each workload operates within its own constrained environment, independent from others. If a module fails, its impact is contained. If it behaves unexpectedly, its access is limited. If it needs to be updated or replaced, it can be managed without affecting the rest of the system.
This enables a new level of control.
Code can be:
- deployed independently
- versioned and validated
- restricted in capability
- revoked if necessary
These properties are essential when workloads are dynamic and continuously evolving, as is the case with AI-driven systems. However, the software sandbox does not exist in isolation. It complements the architectural principles introduced earlier.
Separation of concerns was extended beyond software into the structure of the system itself. Responsibilities were isolated across execution contexts, often at the hardware level, to prevent uncontrolled interaction and reduce exposure.
The software sandbox builds on this foundation, the hardware isolation defines where code runs. Software sandboxing defines what that code is allowed to do. Together, they create a layered model of control — one that limits exposure at the system boundary, and constrains behavior within the execution environment.
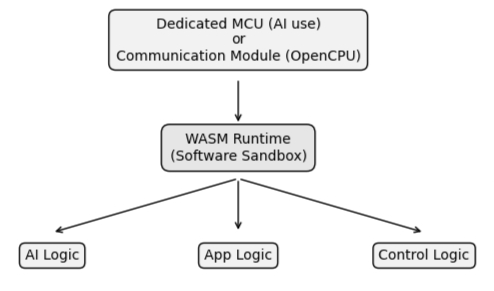
Figure 10: Hardware / Modem Execution with WASM Sandbox
This layered approach is what makes dynamic workloads viable at the edge. Without hardware isolation, exposure cannot be controlled. Without software sandboxing, execution cannot be constrained — both are required.
Why IoT Cannot Use WebAssembly As-Is¶
The execution model provided by WebAssembly aligns closely with the needs of modern Edge systems.
It introduces portability, isolation, and a controlled execution environment — properties that are essential for enabling dynamic workloads at the device level. However, alignment in principle does not guarantee readiness in practice.
WebAssembly was not originally designed for microcontroller-class devices. Its early adoption has taken place in environments with significantly more resources — browsers, servers, and edge gateways. As a result, much of the ecosystem has evolved around assumptions that do not hold at the edge.
These differences are not minor — they are fundamental.
Resource constraints represent the most immediate challenge.
Typical WebAssembly runtimes assume the availability of substantial memory, dynamic allocation, and supporting system services. In contrast, many IoT devices operate with tens of kilobytes of RAM, limited flash storage, and no operating system. Execution must be predictable, bounded, and efficient — trivial in a cloud environment becomes prohibitive on a microcontroller.
Tooling introduces a second challenge.
Many language tool chains that target WebAssembly bring with them significant runtime overhead. Standard libraries, memory management systems, and abstraction layers are often bundled into the resulting binary, even when only a small portion is required.
This increases binary size and complexity, making deployment on constrained devices impractical. In these environments, size is not an optimization concern — it is a feasibility constraint.
A third challenge lies at the boundary between software and hardware. WebAssembly defines how code executes — but not how it interacts with the physical world.
There is no standardized way for a WebAssembly module to access device-level interfaces such as GPIO, I2C, SPI, or UART. As a result, each implementation defines its own approach, creating fragmentation at the very point where portability is most needed.
This fragmentation has consequences. Code written for one environment may not run in another. Modules must be adapted for specific hardware. The promise of portability begins to erode before it can be realized. This reflects the current state of the ecosystem, rather than a limitation of the model itself.
WebAssembly provides the foundation for a new execution model — but additional work is required to make that model viable under real-world IoT constraints. Runtimes must be adapted to operate within strict resource limits.
Tool chains must produce binaries suitable for embedded environments. Interfaces must be defined to allow controlled interaction with hardware. Until these gaps are addressed, WebAssembly cannot fully deliver on its promise at the edge.
The opportunity, however, is clear.
The execution model is already aligned with the needs of IoT. What remains is to bridge the gap between that model and the realities of constrained devices.
The Missing Layer: Hardware Abstraction¶
Even if WebAssembly runtimes become small enough, and toolchains produce binaries suitable for constrained devices, a fundamental problem remains.
How does portable code interact with physical hardware?
WebAssembly defines a standardized execution model. It ensures that code can run consistently across environments. It provides isolation, determinism, and a clear boundary between the module and the system.
It does not define how that code communicates with the real world. In traditional firmware models, this interaction is tightly coupled to the hardware.
Developers use vendor-specific SDKs to access peripherals such as GPIO, I2C, SPI, and UART. These interfaces are implemented differently across platforms, and often expose proprietary abstractions that are deeply integrated into the firmware. This is manageable when software is written specifically for a single device.
It breaks down when portability is introduced.
Without a standardized way to access hardware, WebAssembly modules cannot remain portable. Each runtime must define its own interface. Each device must expose its own abstractions. Each workload must be adapted to its environment. This recreates the same problem WebAssembly is intended to solve.
Portability is lost at the boundary.
This is the missing layer. A mechanism is required to bridge the gap between portable execution and device-specific capabilities. This mechanism must provide a consistent interface for interacting with hardware, while preserving the constraints and isolation defined by the execution environment.
In practical terms, this means defining a set of standardized interactions.
Operations such as reading from a sensor, writing to a pin, or communicating over a bus must be exposed in a way that is independent of the underlying hardware implementation.
The module expresses intent — the system provides the implementation.
This separation is critical. It allows hardware-specific complexity to be handled once, at the system level, rather than repeatedly within each workload. It also ensures that modules remain portable, as they no longer depend on vendor-specific APIs.
Without this, WebAssembly becomes another runtime tied to specific platforms.
With it, it becomes a true abstraction. This is where the execution model becomes viable. A portable format alone is not enough. A consistent interface to the physical world is required to complete the system.
Separation of Concerns Meets WebAssembly¶
The concepts introduced so far — workloads, sandboxed execution, and controlled interaction with hardware — do not exist in isolation.
They depend on the structure of the system in which they operate.
Separation of concerns was extended beyond software and into the architecture of the device itself. Responsibilities such as application logic, connectivity, security, and lifecycle management were no longer combined within a single execution environment. Instead, they were distributed across independent contexts, often enforced at the hardware level.
This separation was not only about organization — it was about control.
WebAssembly does not replace this model. It fits into it. The introduction of a software sandbox complements the architectural separation already established.
While hardware isolation defines where responsibilities reside, WebAssembly defines how logic is executed within those boundaries. Each layer addresses a different dimension of the problem.
At the system level, separation ensures that concerns such as connectivity and security are isolated from application logic. This limits exposure and prevents uncontrolled interaction between critical components.
At the execution level, sandboxing ensures that the logic itself operates within defined constraints, regardless of its origin or purpose.
Together, these layers create a cohesive model.
Application logic and AI workloads can be delivered as portable modules, executed within a constrained environment, and prevented from directly interacting with sensitive parts of the system.
At the same time, communication, security, and lifecycle management remain within controlled domains, isolated from the variability of application behavior.
This alignment is important. Without architectural separation, a sandboxed execution model has limited impact — code may be constrained, but the system itself remains exposed.
Without a sandboxed execution model, architectural separation alone is insufficient — logic may be isolated at a structural level, but cannot be controlled once executed. Both are required.
Separation of concerns provides the structure — WebAssembly provides the execution model. Together, they enable a system in which dynamic workloads can be introduced safely, updated independently, and managed over time without compromising stability or security.
This is not a replacement of existing approaches. It is an integration of them.
The architecture defines the boundaries — the execution model defines the behavior within those boundaries.
Native and WebAssembly: A Dual Execution Model¶
The introduction of WebAssembly does not imply the replacement of native execution. It introduces an additional layer.
In practical systems, native firmware remains essential.
It provides direct access to hardware, enables performance-critical operations, and establishes the foundation upon which the rest of the system operates. Drivers, communication stacks, security primitives, and specialized processing capabilities are often tightly coupled to the device and must remain so.
These capabilities are not easily abstracted away. Nor should they be. WebAssembly operates at a different level. It is designed to execute portable logic within a constrained environment, independent of the underlying hardware.
It allows functionality to be delivered, updated, and managed without modifying the core system.
These two models are not in conflict — they are complementary.
This creates a dual execution model. Native execution handles what must be tightly integrated with the hardware. WebAssembly handles what must be portable, adaptable, and independently managed. This separation aligns naturally with the architectural principles introduced earlier.
Low-level functionality remains within controlled domains, often isolated within dedicated execution contexts. Higher-level logic — application behavior, decision-making, AI-driven workflows — can be delivered as modular workloads, executed within a sandbox.
The interaction between these layers is explicit.
WebAssembly modules do not directly access hardware or system resources. Instead, they rely on interfaces provided by the system — mechanisms that expose specific capabilities in a controlled and predictable way.
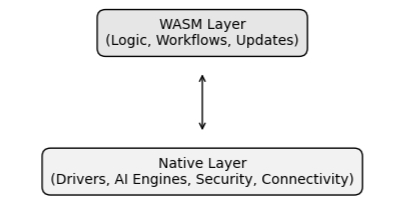
Figure 11: Dual Execution Model: Native and WASM Layers
This is where the model becomes particularly powerful. These interfaces can be defined to expose native functionality. Capabilities such as communication services, cryptographic operations, storage access, or even AI inference engines can be made available to WebAssembly modules through well-defined interfaces.
The underlying implementation remains native, optimized for the hardware, and fully controlled by the system.
The module simply consumes the capability. This creates a clear separation of responsibilities. The system provides capability. The module defines behavior.
In practical terms, this allows advanced functionality to be reused without being embedded directly into every workload. AI models, inference engines, or specialized processing pipelines can be implemented once at the system level, and then accessed by multiple modules as needed.
This approach avoids duplication. It reduces complexity within workloads. It ensures that critical functionality remains under system control. It allows performance-sensitive operations to remain native, while still enabling flexible, portable logic at a higher level.
It also reinforces the sandbox model.
Modules operate within defined boundaries, interacting only through approved interfaces. The system retains control over what is exposed, how it is accessed, and under what conditions.
This is not simply coexistence. It is a division of responsibility. Native execution provides capability — WebAssembly provides adaptability. Together, they enable systems that are both efficient and flexible — capable of running optimized, hardware-specific functionality while still supporting dynamic, portable workloads.
Lifecycle Management as the Control Plane¶
The introduction of workloads, sandboxed execution, and a dual execution model expands what Edge systems are capable of.
It also introduces a new requirement: how these systems are managed over time.
Defining how code executes is only part of the problem. In real-world deployments, devices operate across distributed environments, often with limited connectivity and long operational lifetimes. They must be updated, monitored, and controlled without direct access, and without compromising stability.
This is where lifecycle management becomes central.
In more traditional systems, lifecycle management is often treated as a supporting function — responsible for delivering updates, maintaining connectivity, and providing visibility into device state. While important, it typically operates alongside the system rather than defining it.
As systems move toward dynamic workloads, this distinction begins to change.
Workloads must be delivered in a controlled and predictable way. Updates must be applied without disrupting other parts of the system. Behavior must be observable over time, and access to functionality must be governed, limited, and, when necessary, revoked.
These are not isolated concerns. They shape how the system operates as it evolves. The same applies to AI-driven functionality. Models may be refined continuously, but without a reliable mechanism to distribute and manage those updates across a fleet, that refinement cannot be effectively realized in practice.
The ability to evolve becomes dependent not only on the execution model, but on how that execution is managed over time.
This highlights an important distinction.
Execution models define how logic runs. Lifecycle management defines how that logic is introduced, maintained, and controlled. At scale, this becomes increasingly significant. Devices may remain in operation for years, often in environments where direct intervention is not feasible. They must adapt to new requirements, respond to emerging threats, and incorporate new capabilities without compromising reliability.
Managing this process requires more than periodic updates.
It requires a structured approach to control. In this context, lifecycle management becomes the layer through which the system is coordinated. It governs how workloads are deployed, how updates are applied, and how behavior is monitored over time. It provides a consistent mechanism for managing both native functionality and portable workloads, ensuring that each evolves within defined boundaries.
This does not replace the underlying architecture or execution model.
It connects them. Separation of concerns establishes the structure of the system. WebAssembly provides a portable and constrained execution environment.
Lifecycle management ensures that both can operate effectively over time. Taken together, these elements form a system that is not only capable, but manageable.
Industry Implications¶
The combination of architectural separation, portable execution, and lifecycle management does more than change how individual systems are built.
It begins to shift how the broader IoT ecosystem operates. In traditional models, software is tightly coupled to hardware. Applications are developed against vendor-specific SDKs, deployed as part of a single firmware image, and maintained within the constraints of a particular platform.
This creates dependencies that extend beyond the device itself — affecting development workflows, integration strategies, and long-term maintenance. As a result, flexibility is limited.
Changing hardware often requires rewriting software. Integrating third-party logic introduces risk. Maintaining systems over long lifetimes becomes increasingly complex. These constraints are well understood, but difficult to avoid within the existing model.
The introduction of portable workloads begins to alter this dynamic.
When logic can be delivered independently of firmware, and executed within a constrained environment, the dependency between software and hardware starts to loosen. The same workload can be deployed across different devices, provided that a consistent execution model and interface are available.
This has practical implications.
Hardware selection becomes less restrictive, as software is no longer tightly bound to a specific vendor implementation. Updates can be applied at a finer level of granularity, reducing the need for full system replacement. New functionality can be introduced incrementally, rather than as part of large, coordinated releases.
It also affects how software is developed and shared.
When execution is sandboxed and interfaces are clearly defined, it becomes possible to introduce logic from multiple sources without requiring full integration into a single codebase.
This does not eliminate the need for validation or control, but it provides a framework in which such contributions can be managed more safely.
Over time, this enables a more modular ecosystem.
Functionality can be developed, deployed, and maintained as independent units. Systems can evolve without being entirely rebuilt. The relationship between hardware vendors, software providers, and system integrators becomes less rigid, allowing each to operate with greater independence.
These changes do not occur immediately.
They depend on the adoption of consistent execution models, the definition of stable interfaces, and the presence of reliable lifecycle management. Without these elements, the system remains fragmented, and the benefits of portability are limited.
However, the direction is clear. As devices are expected to operate longer, adapt more frequently, and support increasingly complex functionality, the constraints of tightly coupled systems become more pronounced.
Approaches that enable separation, controlled execution, and independent evolution begin to offer a more sustainable path forward.
This does not replace existing ecosystems overnight.
It introduces a gradual shift. One in which control moves from tightly bound implementations toward more flexible, layered systems — where responsibilities are clearly defined, interaction is controlled, and evolution is managed over time.
Transitioning Forward¶
The concepts explored — workloads, portable execution, sandboxing, and lifecycle control — are not independent developments.
They are part of a broader shift in how Edge systems are designed and operated.
Taken together, they point toward a model in which devices are no longer defined solely by their hardware or initial firmware, but by their ability to evolve over time.
Functionality becomes something that can be introduced, updated, and managed independently, while the underlying system provides the structure and control required to support that evolution.
This shift does not occur in isolation.
It builds on the architectural foundations introduced earlier — where separation of concerns and controlled interaction define how systems are structured.
It extends those foundations with an execution model that enables portability and constrained behavior, and with a lifecycle approach that allows systems to operate reliably over extended periods.
The result is a system that is not only capable of change, but designed for it.
At this stage, the individual components of the model begin to align — architecture defines boundaries, execution defines behavior, and lifecycle management defines control.
Together, they establish the conditions required for dynamic, long-lived systems at the edge. What remains is how these principles are applied in practice.
- how are these layers implemented in real-world systems?
- how are workloads delivered, validated, and managed across fleets?
- how is control maintained as systems scale and evolve?
These are not abstract questions.
They define the difference between a conceptual model and an operational system.
The next step is to examine how these ideas are realized in practice — and how they can be applied to address real-world requirements in production environments.